Fetch & Prefetch
拾取与预解码
处理器在执行指令之前,必须先装载指令,这就是Fetch阶段,通常是流水线的第1级。指令会先保存在L1缓存的I-cache(Instruction-cache)指令缓存当中,Godson2的L1 I-cache容量为64KB(D-cache同样为64KB),比Nehalem大一倍。和Nehalem一样,Godson的指令拾取单元使用128bit带宽的通道从I-cache中读取指令——一次可以读取4条指令(也和Nehalem一样)。Godson2的I-cache采用和Nehalem的I-cache一样都采用了4路集合关联(不同的是Nehalem的D-cache是8路集合,Godson2 D-cache仍然为4路),我们知道Nehalem这种比Core更少的集合关联数量是为了降低延迟。
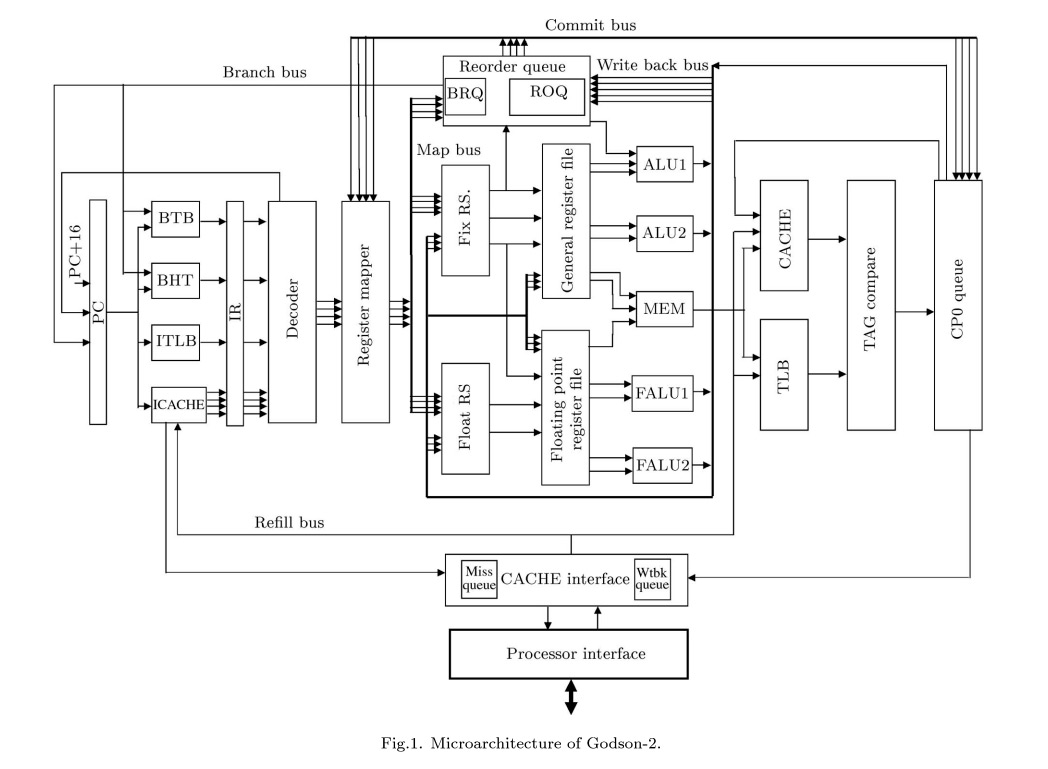
Godson-2 Microarchitecture
通过PC(Program Counter,程序指针)拾取到指令之后,指令被发往Instruction Register指令寄存器,并进入下一个阶段:pre-decode,这个阶段的存在是为了实现分支预测功能,分支预测是为了充分发挥乱序执行效能而出现的功能,通过预测如if then这样的语句的将来走向,提前读取相关的指令并执行的技术,可以明显地提升性能。
龙芯2具有16个条目的BTB(Branch Target Buffer,分支目标缓冲区)和4K条目的BHT(Branch History Table,分支历史表),BTB用来保存预测指令的地址,BHT则统计历史分支。Nehalem具有两层BTB结构,不过细节不详。BHT包括了一个9位的GHR(Global History Register,全局历史寄存器)和实际保存4K条目内容的PHT(Pattern History Table,原历史表)。

Nehalem RSB:重命名的返回堆栈缓冲器
在Nehalem上,与BTB相对的是RSB(Return Stack Buffer,返回堆栈缓冲区),而MIPS指令集并没有Call和Return指令,分支由通常的Branch/Jump/Link以及jump register 31指令来实现,然而龙芯2上通过特别的方法也实现了和RSB对应的RAS(Return Address Stack,返回地址堆栈),它在预解码到Branch/Link就将PC+8压入RAS,预解码到jump register 31指令就将RAS弹出到PC,从而实现了类似的功能。RAS容量为4个条目,不算多。

Nehalem: Fetch
指令拾取单元使用预测指令的地址来拾取指令,它通过访问L1 ITLB里的索引来继续访问L1I Cache,龙芯2具有16条目的ITLB,Nehalem具有两层TLB:L1具有128条目的小页面ITLB(按照两个线程静态分区)和7条目的全关联(Full Associativity)大页面ITLB,这些TLB用于访问2M/4M的大容量页面;L2 TLB则和L2缓存一样,指令/数据共用。
预解码结束之后将会被送往下一个流水线阶段:解码。

